For prompt assistance please contact us using this information.
AccessibleWebBot
AccessibleWebBot is the name of Accessible Web’s bot that scans sitemaps for newly added pages, as well as pages that users of the Accessible Web RAMP have requested be scanned for accessibility issues. You may see this bot with either of the following user agents.
Mozilla/5.0 (compatible; AccessibleWebBot/1.0; +https://accessibleweb.com/bot/)Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko; compatible; AccessibleWebBot/1.0; +https://accessibleweb.com/bot/) HeadlessChrome/W.X.Y.Z Safari/537.36
The bot will always scan websites from an IP address affiliated with the domain accessiblewebbot.com. If you receive traffic from a bot with user agents like the ones above, you can verify the authenticity of the requests by running a reverse DNS lookup on the IP address and making sure the domain matches.
The Chrome version, denoted above as W.X.Y.Z will change over time as we take Chrome updates.
How AccessibleWebBot Scans Websites
When a user in the Accessible Web RAMP changes the sitemap URL field on one of their websites, Accessible Web will rescan the new location to see what has changed. In addition, AccessibleWebBot will check the sitemap periodically from that point forward so it can notify the owner of the site of additions so they can keep an eye on their accessibility.
AccessibleWebBot also does periodic scans of certain pages to check for accessibility issues. The pages that are scanned are determined from the scanning frequency set in the Accessible Web RAMP.
If you notice traffic from AccessibleWebBot but do not have an account with Accessible Web, please get in contact with us.
Blocking AccessibleWebBot
To prevent AccessibleWebBot from visiting your website’s sitemaps, simply remove the sitemap from the website in your Accessible Web RAMP account. Similarly, if you would like the bot to no longer scan certain pages for accessibility issues, you can either remove the pages from Accessible Web RAMP, or set their scanning frequency to “Don’t scan”.
Alternatively, you may specify rules in your site’s file for Accessible Web to follow. The following entry in your robots.txt will block the AccessibleWebBot from the entire site.
User-agent: AccessibleWebBot
Disallow: /Allowing AccessibleWebBot
AccessibleWebBot should scan your website correctly if your robots.txt is allowing search engines. You can check to verify that it contains the following lines which allows all User Agents to crawl the entire site.
User-agent: *
Allow: /If you have lines in your robots.txt with specific pages that are blocked from other search engines, you can specify that AccessibleWebBot is allowed to scan them using the following example. In the example below, Googlebot is prevented from crawling /cart/, /checkout/, and /wp-admin/ while AccessibleWebBot is given permission to scan these pages.
User-agent: Googlebot
Disallow: /cart/
Disallow: /checkout/
Disallow: /wp-admin/
User-agent: AccessibleWebBot
Allow: /cart/
Allow: /checkout/
Allow: /wp-admin/If you find that the AccessibleWebBot is not following these rules, please contact us to resolve the issue.
IP Address Filtering
If you need to either allow or disallow AccessibleWebBot based on the IP address of network traffic, please contact us.
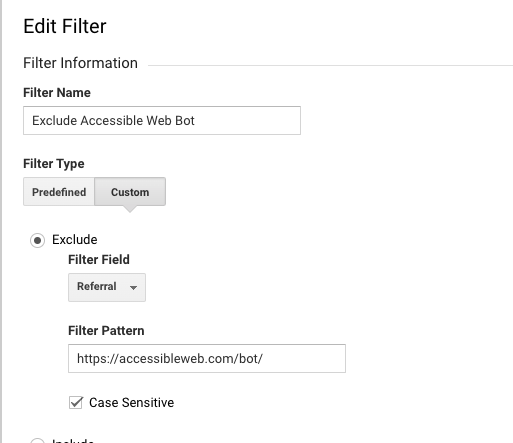
Filter from Website Analytics
To filter our bot from showing up in your analytics accounts, like Google Analytics, you can filter out referral traffic from this page. Before our bot visits a page on your website, it will set its referrer to https://accessibleweb.com/bot/. In google analytics for example, you are able to filter a view by traffic from this referrer.